
转写自组会上讲解使用的 Slides,高度凝练了 DATA100 中 Pandas 的教学内容。
1. Pandas 简介
-
什么是 Pandas ?
- 一个开源的数据分析和处理 Python 库,基于 NumPy。
- Like a Python module version of SQL
-
为什么 Pandas ?
- 提供了快速、灵活和表达式丰富的数据结构,使 “关系” 和 “标签” 数据的处理既简单又直观。
- Highly compatible wito NumPy
- Popular
2. Pandas 使用的基础数据结构
-
Pandas 处理的基本数据类型:Tabular Data
-
基本数据结构
-
Series:1D tagged data structure,类似于 Python 中的dict。 -
DataFrame:2D tagged data structure,以 Series 为列构成的 2D table 。 -
DataFrameGroupBy:DataFrame.groupby的产物,是多组有共同特征的 DataFrames 集合。
-
3. 数据处理的基本操作
-
Read Data:
- Create a DataFrame from a file or from a Python object.
-
Select Data:
- Select rows, columns, or cells from a DataFrame.
-
Filter Data:
- Define conditions, generate boolean masks, and filter data.
-
Sort Data:
- Sort data by the index we specify.
-
Aggregating Data:
- Group data by some criteria and apply functions to the groups.
-
Join Data:
- Combine DataFrames based the key columns we specify.
-
Modify Data
-
Delete Data
3.1 Read Data
From csv file or dict, list, tuple, ndarray, Series objects in Python.
1 | import pandas as pd |
3.2 Select Data
-
Select Columns: Use column names directly or
df[['col1', 'col2']]. -
Select Rows: Use slicing or conditions, e.g.,
df[1:3]ordf[df['Age'] > 20]. -
Select Cells: Combine row and column selection, e.g.,
df.loc[rows, cols]ordf.iloc[row_indices, col_indices].
3.2 Select Data
1 | # Select a single column |
3.3 Filter Data
1 | # Simple condition |
3.4 Sort Data
Sorting data is crucial for analyzing datasets where the order of rows is significant.
1 | # Sort DataFrame by a single column |
3.5 Aggregating Data
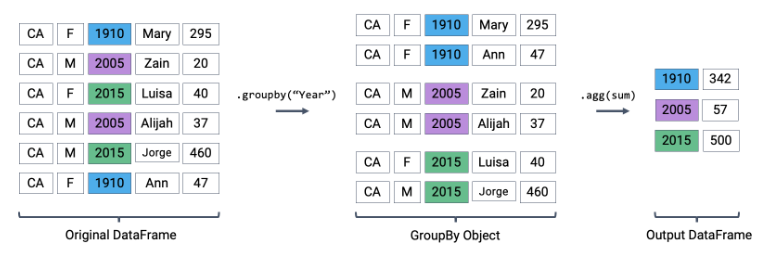
3.5.1 Aggregating Data
Aggregating data involves combining multiple pieces of data into a summary form.
1 | # Group by a single column and calculate mean |
3.5.2 Aggregating Data with Pivot Tables
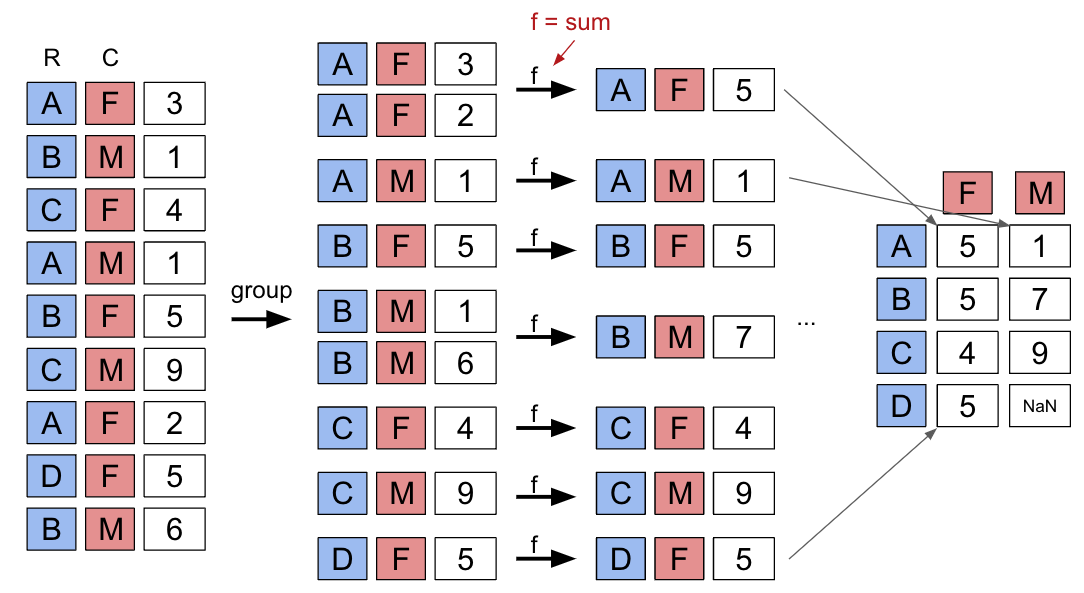
3.5.2 Aggregating Data with Pivot Tables
1 | # The `pivot_table` method is used to generate a Pandas pivot table |
3.6 Join Data
leftandrightparameters are used to specify the DataFrames to be joined.left_onandright_onparameters are for aligning the key columns.
1 | # Merge two DataFrames on a key |
3.7 Modify Data
1 | # Change a value directly |
3.8 Delete Data
1 | # Drop a column |